
Data ethics and governance
To keep data safe, we adhere to the Five Safes model. Devised by the Office for National Statistics and developed over decades alongside other providers, the Five Safes framework serves as best practice in data protection while also balancing requirements for open science and transparency. It is a set of established safeguards and measures to ensure organisations keep data safe and secure.
Each of the Five Safes is described in more detail, along with how it aligns with SENSE governance processes.
-
Is there a disclosure risk in the data itself?
In SENSE, we have a data triage process and if a data risk is identified, for example disclosure of personal information or commercially sensitive information, appropriate mitigations are mandated, for example anonymisation, aggregation and restricting access.
-
Does the access facility limit unauthorised use?
Throughout the SENSE platform access to data is subject to industry standard access control (using the Keycloak service). Users registered on the platform must use multi factor authentication. The platform has three tiers of access control, with individual users being granted access to individual resources, which they can access only with their platform user credentials.
Open - all service users may freely download or use
Safeguarded - metadata is visible to all and service users may apply for access and may be granted access subject to review of the application.
Secure - minimal description is available to all and service users must apply for access to view or use the data. If approved, access may be time limited or have further restrictions on where data may be processed.
-
Can the researchers be trusted to use data in an appropriate manner?
Open data are available to all service users, those wishing to use safeguarded or private data must apply for access. They must apply for access from their registered account, with details of their institution and their intended use. Prior to access being granted we ensure that researchers explicitly consent to licenses and protecting confidentiality by signing an agreement and demonstrate the technical skills needed to use the data safely. Where necessary, for access to the most sensitive data, evidence of Safe Researcher Training course pass will be required.
-
Is this use of the data appropriate?
Open data are available to all service users, those wishing to use safeguarded or private data must apply for access. That application requires researchers to describe the project for which the data is required and intended use. This is assessed as part of our ethical processes to identify any risk due to intended use and, if approved, researchers are required to explicitly consent to a license agreement which states that data will only be used for the purposes described in the application.
-
Are statistical results of work with the data non-disclosive?
If risks of disclosure are identified, restrictions on output publication are imposed, including the potential to mandate that all outputs are screened and approved by the SENSE team for the most sensitive scenarios.
Data Ethics Board
Our Data Ethics Board meets quarterly to review applications for access to safeguarded data, ensuring compliance with ethical standards and data protection regulations. Scheduled meetings are:
April 2026
July 2026
October 2026
January 2027
Where possible, SENSE aims to communicate decisions on high-risk (and selected moderate-risk) applications by the end of the relevant review month. While the board aims to make this process as efficient as possible, it may take up to 3 months to complete, depending on the next scheduled meeting.
If an urgent decision is required, the Chair may convene an extraordinary review.
-
SENSE makes high-value energy datasets available for research and innovation. While responsible data sharing can accelerate progress toward Net Zero, it must be done in a way that protects individuals, communities, infrastructure, and the integrity of the research ecosystem.
The SENSE Ethics Board provides independent ethical oversight of:
High-risk datasets proposed for ingestion into the SENSE platform; and
High-risk applications seeking access to SENSE data.
The Board ensures that data is shared responsibly, proportionately, and in line with legal, ethical, and public interest considerations. Its role is to safeguard against potential harms, including privacy risks, misuse of sensitive information, unfair commercial advantage, or unintended impacts on consumers and communities.
-
The Board:
Reviews datasets and applications classified as high risk under the SENSE Five Safes framework.
Assesses whether proposed uses are justified, proportionate, and aligned with public benefit.
Recommends mitigations where risks can be reduced (e.g. aggregation, secure access environments, output controls).
Provides independent judgement where risks are novel, complex, or contested.
The Board does not review every application. Most low and moderate risk datasets and requests are processed through SENSE’s ethics and governance procedure. The Ethics Board is engaged when additional scrutiny is necessary, for example, accessing datasets of a higher risk.
-
The Board’s review is guided by the Five Safes Framework:
Safe Projects: Is the purpose appropriate and in the public interest?
Safe People: Are applicants suitably qualified and accountable?
Safe Data: What are the privacy, legal, commercial, and ethical risks?
Safe Settings: Is access provided in a secure and proportionate way?
Safe Outputs: Can results be shared without exposing sensitive information?
Board members draw on their experience in data ethics, engineering policy, digital governance, and responsible innovation when reaching decisions.
The board will make the following decisions:
• Approval
• Approval if specific conditions are followed – e.g., additional mitigations and/or output checks
• Rejection – if proposed dataset or application is at an unacceptable level of risk, despite any stated mitigations. Applicants may revise and resubmit the application -
Applicants or data providers whose dataset or application has been rejected have the right to appeal.
Grounds for appeal (non-exhaustive)
You believe the Board’s reasoning contains a material error of fact or interpretation. E.g. The board flagged regulatory concerns which are not relevant.
You can propose additional mitigations that materially reduce the identified risks (e.g. reduced dataset scope, secure environment use).
You can present new evidence or clarification addresses the Board’s stated concerns.
-
Appeals must be submitted in writing within 30 days of the decision.
Appeals should clearly state the grounds and include any supporting evidence or revised safeguards.
Appeals should be addressed to the SENSE Ethics Board email: sense.ethicsboard@es.catapult.org.uk
The Chair will conduct an initial review. If appropriate, the matter will be reconsidered by the full Ethics Board. The Chair’s decision on whether an appeal proceeds to full reconsideration is final.
-
Applicants may resubmit a revised application at any time, provided the new submission addresses the issues that led to rejection.
Resubmissions follow the standard application process and will be reassessed independently of the earlier decision.
Where relevant, applicants should highlight changes made in response to previous feedback (e.g. new mitigations, revised methodology, secure environment proposal).
Transparency and accountability
SENSE is committed to transparent and proportionate governance. We will:
Publish high-level summaries of our governance approach.Maintain clear documentation of decision-making processes.Periodically review the Ethics Board’s Terms of Reference to reflect evolving best practice in data ethics and AI governance.
Members of the SENSE Ethics Board
Synthetic data
In the age of powerful artificial intelligence models, data is the one of the most valuable commodities for developing accurate and informative insights. Where there is data scarcity or privacy concerns with sharing data, an increasingly important approach for supporting data-driven tools is synthetic data.
What is synthetic data?
Synthetic data is information that is artificially generated, while attempting to maintain statistical properties, relationships and structure of the real data it is attempting to emulate. In many cases, this data is generated from samples of the real data to learn key properties that increase its utility in the intended applications, otherwise any results may not be valid or may create false insights.
Energy Case Study
Although synthetic data has been used relatively frequently within applications such as health, their use in the energy sector has been relatively sparse. One prominent recent example has been the OpenSynth community. Originally focused on household energy usage, utilising Centre for Net Zero’s synthetic smart meter model Faraday, it has now extended to include synthetic network data based on the French transmission grid. This enables the development of tools for power system modelling and grid topology optimisation.
Balancing Privacy and Utility
Synthetic data isn’t intended to create a one-to-one mapping with real instances so should make identification of real individuals’ information impossible or very difficult. Where synthetic data is properly anonymous then sensitive information cannot be extracted from the data, in the case of dealing with personal information this means data protection laws do not apply to the synthetic data.
Often there is a trade-off between fidelity of the synthetic data (how representative it is of the actual data) and the privacy, where the chances of re-identification increase as the data starts to capture more properties and structure of the real data. This also means that you often have to balance utility and privacy, since more realistic data also means the data is likely to lead to improved testing and model development.
The UK Synthetic Data Community Group has categorised synthetic data into different categorisations based on fidelity levels. It is categorised from the lowest level (“Structural”) where the data is generated solely from metadata and has no relationship to the actual data, up to the highest (“augmented”) which is synthetic data which is used to generate new unrepresented or unseen cases in the true dataset sample. The figure below shows that as the fidelity of the synthetic data increases it gains more features and structure of the true underlying demand.
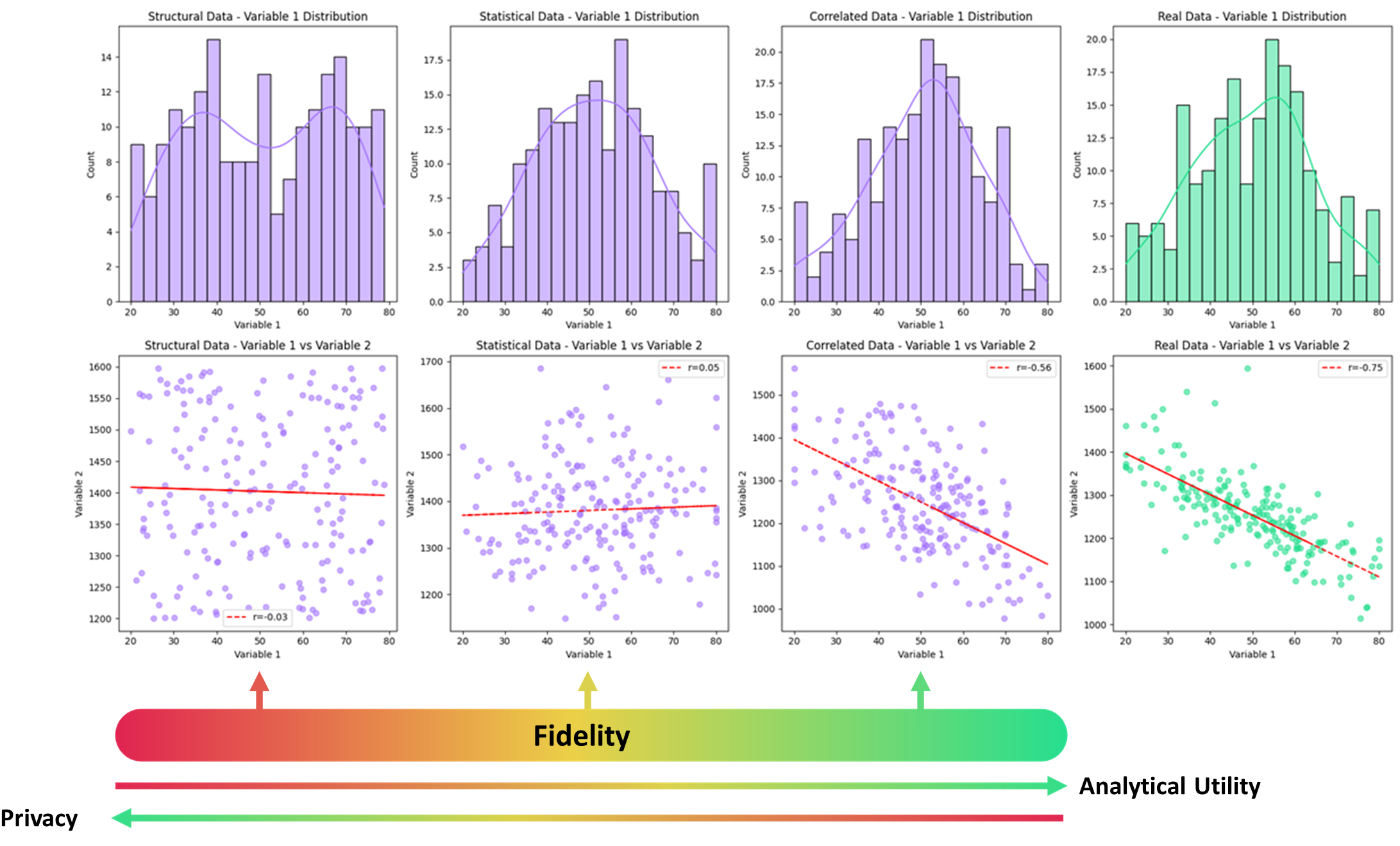
Illustration of synthetic data at different fidelity levels (increasing from left to right), increases the features captured in the synthetic data from the original. Taken from this report and used under CC BY 4.0 License.
Often privacy or sensitives are only exposed if the data can be linked to other datasets which can help identification, or if some of the features are unique (for example when a value is extreme). For this reason, possible data linkages and outlier features need to be carefully considered when developing a synthetic dataset.
In addition to developing robust data governance, there are several ways to try and ensure the synthetic data does not expose sensitive data. For example, motivated intruder tries to evaluate the privacy and re-identification risk by determining if an attacker is able to gain access to this sensitive information using reasonable effort and available resources. Often when generating synthetic data the outputs are combined with robust privacy enhancing techniques like differential privacy which can help guarantee particular levels of privacy.
Synthetic data within SENSE
Although SENSE will be collecting valuable datasets to support research in our core applications, there will also be sensitive information which cannot be shared openly.
One of the first areas where we are going to create synthetic data for the SENSE platform will be public EV charging profiles. This is a prime candidate for synthetic data, as using raw data for these profiles can potentially reveal commercially or personally sensitive information, which restricts access. We are utilising both domain expert knowledge and publicly available data to ensure we capture the diversity and veracity of EV charging behaviours. This ensures not only that we can develop models of how EV usage interacts with networks, transport and other services, but also how this varies with different user types.
To ensure responsible development of this synthetic data we are also running a synthetic data group within SENSE. We are always looking for additional experts to join the team, so if you are interested in being part of this, please contact the SENSE team at sense@es.catapult.org.uk
Licence types
The most common types of licence can be found in the table below with their most distinguishing features. Please follow the links to view the full licence conditions.
Looking for a licence to share your dataset?
Please contact us sense@es.catapult.org.uk if you wish to share a dataset under a licence that doesn't appear in the table below or you have any queries about selecting the most appropriate licence as you may need a custom licence which we can help you with.
Open licences:
UK Open Government Licence (OGL-3.0) (Attribution + link to licence + citation)
Open Data Commons Open Database License (ODbL) (Attribution + share-alike (copyleft))
Open Data Commons Public Domain Dedication and License (PDDL) (Public domain (all rights waived))
Open Data Commons Attribution License (ODC-By) v1.0 (Attribution)
Creative Commons Zero (CCO-1.0) (Public domain (all rights waived))
Creative Commons Attribution (CC-BY-4.0) (Attribution required only)
Creative Commons Attribution ShareAlike (CC-BY-SA-4.0) (Attribution + share-alike (copyleft))
Creative Commons Attribution NonCommercial (CC BY-NC-4.0) (Attribution + non-commercial use only)
Creative Commons Attribution NonCommercial ShareAlike (CC BY-NC-SA-4.0) (Attribution + non-commercial use only + share-alike (copyleft))
Permissive licences:
GNU Free Documentation (GFDL) v1.3 (Attribution + share-alike (copyleft), preserve copyright notices, maintain invariant sections and provide full licence text)
MIT (Include original copyright notice and licence text in software)
Apache-2.0 (Preserve copyright, patent and trademark notices, provide copy of the licence and detail significant changes made to files)
Bespoke:
Custom (Highly specific terms and restrictions)