
Synthetic data
In the age of powerful artificial intelligence models, data is the one of the most valuable commodities for developing accurate and informative insights. Where there is data scarcity or privacy concerns with sharing data, an increasingly important approach for supporting data-driven tools is synthetic data.

What is synthetic data?
Synthetic data is information that is artificially generated, while attempting to maintain statistical properties, relationships and structure of the real data it is attempting to emulate. In many cases, this data is generated from samples of the real data to learn key properties that increase its utility in the intended applications, otherwise any results may not be valid or may create false insights.
Energy Case Study
Although synthetic data has been used relatively frequently within applications such as health, their use in the energy sector has been relatively sparse. One prominent recent example has been the OpenSynth community. Originally focused on household energy usage, utilising Centre for Net Zero’s synthetic smart meter model Faraday, it has now extended to include synthetic network data based on the French transmission grid. This enables the development of tools for power system modelling and grid topology optimisation.
Balancing Privacy and Utility
Synthetic data isn’t intended to create a one-to-one mapping with real instances so should make identification of real individuals’ information impossible or very difficult. Where synthetic data is properly anonymous then sensitive information cannot be extracted from the data, in the case of dealing with personal information this means data protection laws do not apply to the synthetic data.
Often there is a trade-off between fidelity of the synthetic data (how representative it is of the actual data) and the privacy, where the chances of re-identification increase as the data starts to capture more properties and structure of the real data. This also means that you often have to balance utility and privacy, since more realistic data also means the data is likely to lead to improved testing and model development.
The UK Synthetic Data Community Group has categorised synthetic data into different categorisations based on fidelity levels. It is categorised from the lowest level (“Structural”) where the data is generated solely from metadata and has no relationship to the actual data, up to the highest (“augmented”) which is synthetic data which is used to generate new unrepresented or unseen cases in the true dataset sample. The figure below shows that as the fidelity of the synthetic data increases it gains more features and structure of the true underlying demand.
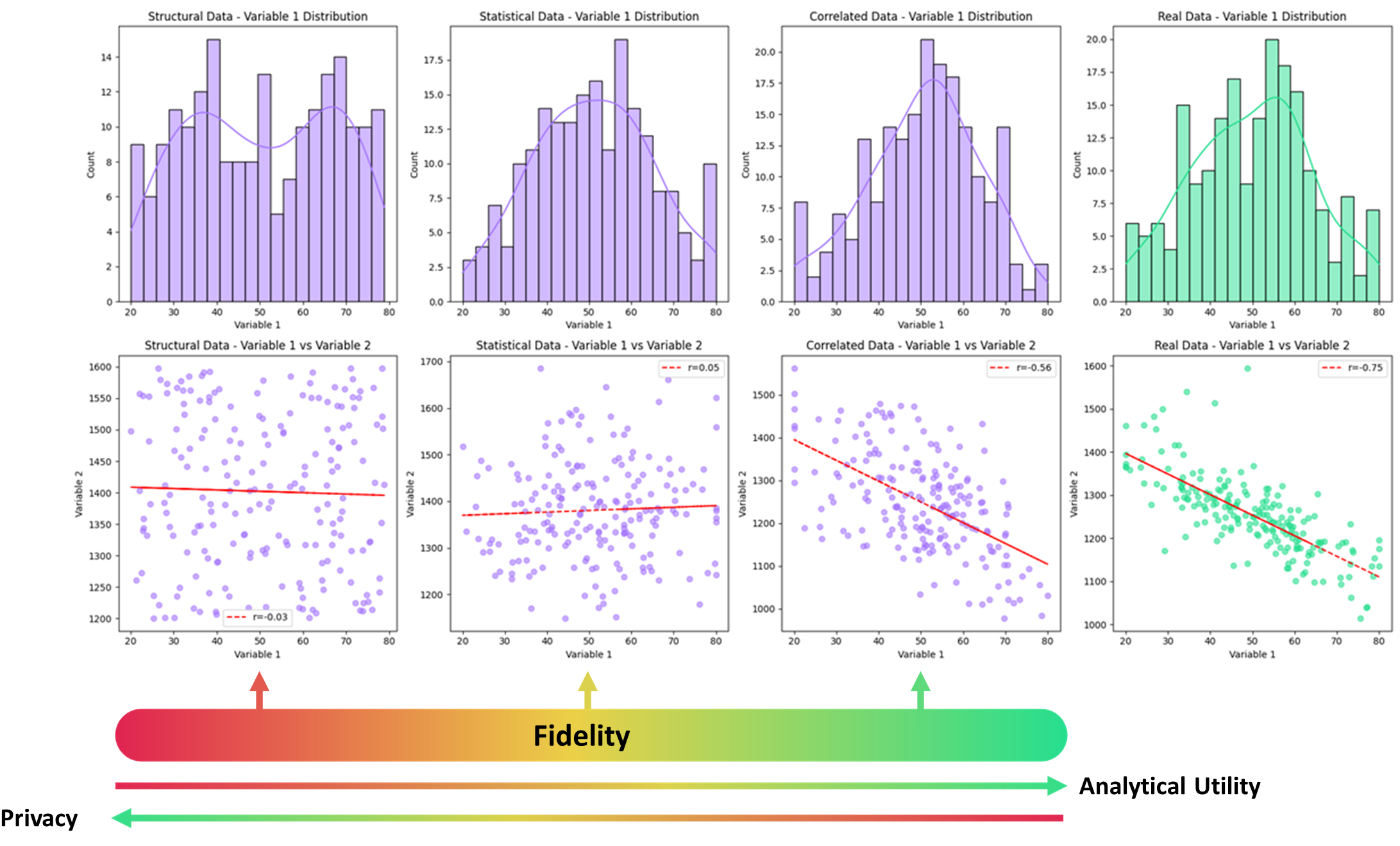
Illustration of synthetic data at different fidelity levels (increasing from left to right), increases the features captured in the synthetic data from the original. Taken from this report and used under CC BY 4.0 License.
Often privacy or sensitives are only exposed if the data can be linked to other datasets which can help identification, or if some of the features are unique (for example when a value is extreme). For this reason, possible data linkages and outlier features need to be carefully considered when developing a synthetic dataset.
In addition to developing robust data governance, there are several ways to try and ensure the synthetic data does not expose sensitive data. For example, motivated intruder tries to evaluate the privacy and re-identification risk by determining if an attacker is able to gain access to this sensitive information using reasonable effort and available resources. Often when generating synthetic data the outputs are combined with robust privacy enhancing techniques like differential privacy which can help guarantee particular levels of privacy.
Synthetic data within SENSE
Although SENSE will be collecting valuable datasets to support research in our core applications, there will also be sensitive information which cannot be shared openly.
One of the first areas where we are going to create synthetic data for the SENSE platform will be public EV charging profiles. This is a prime candidate for synthetic data, as using raw data for these profiles can potentially reveal commercially or personally sensitive information, which restricts access. We are utilising both domain expert knowledge and publicly available data to ensure we capture the diversity and veracity of EV charging behaviours. This ensures not only that we can develop models of how EV usage interacts with networks, transport and other services, but also how this varies with different user types.
To ensure responsible development of this synthetic data we are also running a synthetic data group within SENSE. We are always looking for additional experts to join the team, so if you are interested in being part of this, please contact the SENSE team at sense@es.catapult.org.uk